Below you will find frequently asked questions, divided over four different groups. First, a generic FAQ with information applying to a broad set of master degrees and then more specific FAQs applying to specific programs only.
FAQ for all master degrees

“Signal Processing in the AI era” was the tagline of this year’s IEEE International Conference on Acoustics, Speech and Signal Processing, taking place in Rhodes, Greece.
In this context, Brent de Weerdt, Xiangyu Yang, Boris Joukovsky, Alex Stergiou and Nikos Deligiannis presented ETRO’s research during poster sessions and oral presentations, with novel ways to process and understand graph, video, and audio data. Nikos Deligiannis chaired a session on Graph Deep Learning, attended the IEEE T-IP Editorial Board Meeting, and had the opportunity to meet with collaborators from the VUB-Duke-Ugent-UCL joint lab.
Featured articles:
- De Weerdt, B. et al., “Designing Transformer Networks for Sparse Recovery of Sequential Data Using Deep Unfolding” (https://ieeexplore.ieee.org/abstract/document/10094712)
- Yang X. et al., “Relevance Propagation through Deep Conditional Random Fields” (https://ieeexplore.ieee.org/abstract/document/10095075)
- Stergiou A. et al., “Play it back: Iterative attention for audio recognition” (https://ieeexplore.ieee.org/abstract/document/10096532, developed at the University of Bristol)

Prof. Lesley De Cruz and her team have been selected for the 2026 EMS (European Meteorological Society) Outreach & Communication Award for their innovative workshop that makes urban climate science accessible and engaging. The project uses LEGO bricks and real-time AI modeling to help participants understand how urban design choices affect local temperature patterns.
The workshop operates through a straightforward cycle: participants build miniature cities with LEGO blocks, a custom Temperature Booth scans the physical model, an AI-powered urban climate model processes the data instantly, and participants immediately observe how design modifications (such as replacing parking lots with parks) alter heat distribution patterns. By focusing on nighttime heat retention, the workshop provides intuitive insights into urban planning and climate resilience without requiring prior scientific background.
Since launch, the project has engaged thousands of participants at public events and science festivals. It has also earned recognition in academic circles, including a second place for Best Student Presentation at the 12th International Conference on Urban Climate (2025) and the Royal Flemish Academy’s Science Communication Prize.
The interdisciplinary team includes researchers from VUB and partner institutions RMI, UGent and KdG. The work demonstrates how combining AI, hands-on engagement, and scientific rigor can bridge the gap between complex climate science and public understanding. The award will be presented at the EMS Annual Meeting in Utrecht on September 7, 2026.
This workshop was made possible thanks to funding from Innoviris.


ETRO will be represented at Brussels Climate Week 2026 by Prof. Johan Stiens, who will take part as one of the VUB speakers during the event. Brussels Climate Week brings together experts working on climate, energy, sustainability and the broader transition agenda. The event will take place in Brussels from 12 to 16 October 2026, offering an opportunity to exchange ideas, connect with partners and contribute to the discussion on innovation and decarbonisation.

On 11 May, the Green Energy Park in Zellik welcomed four fifth-year secondary school classes for a Climate Technology Day organised by VUB. Pupils from Sint-Jozefinstituut Ternat, Koninklijk Atheneum Etterbeek and ZAVO Zaventem took part in a varied STEM programme, discovering how engineering, digital technologies and climate innovation come together in the search for sustainable solutions.
A central contribution came from ETRO VUB, represented by Professor Johan Stiens. In his session on the Internet of Things and the transformative role of Big Data, Stiens made a strong case for engineering as a discipline with enormous societal impact. Through concrete examples from everyday life — from laptops and transport to the buildings around us — he showed how engineers shape the world, often invisibly, and why young people should be encouraged to choose engineering and STEM studies.
The day also introduced pupils to broader VUB expertise in climate technology, including electric mobility, wind energy and the Multi-Energy Living Lab at the Green Energy Park. Demonstrations such as the VUB Formula Student race car and the Smart Digital Table Top helped translate complex energy systems into tangible, inspiring experiences for the students.
By combining scientific insight with hands-on demonstrations, the Climate Technology Day gave pupils a vivid impression of what engineering can mean for the future. For ETRO VUB and Professor Johan Stiens, the event was also an opportunity to highlight the importance of electronics, informatics, IoT and data-driven innovation in addressing society’s major challenges — and to motivate a new generation to become part of that effort.

Ruiqi Chen, Abdessamad Nassihi, and Bruno da Silva proudly represented ETRO at the International Symposium on Circuits and Systems (ISCAS 2026) in Shanghai, one of the leading conferences in the field of circuits and systems. They presented two major contributions pushing the boundaries of power-efficient edge computing.
Featured articles:
- “Power-Efficient Spiking Conversion of Deep Unfolded Transformers”; Ahmed Sadaqa
- “IDSPfree: An FPGA-Based Intrusion Detection System with DSP-Free Design”; Abdessamad Nassihi

Researchers involved in the European ENACT project have shown how wearable environmental sensing technology can help capture real-world air-quality events. Following the industrial fire that broke out in Tubize on 25 May 2026, ENACT environmental wearables deployed in Halle, south of Brussels, recorded clear changes in local air-pollution signals, including increases in nitrogen dioxide and volatile organic compound measurements.
The VUB ETRO department contributes to ENACT’s work on environmental monitoring technologies and data-driven analysis, supporting the development of tools that can help researchers better understand how environmental exposure affects health. The measurements collected during this incident provide a concrete example of how wearable sensing can complement official monitoring networks and contribute to future exposomic risk assessment.
Further analysis will refine the raw sensor readings by comparing them with reference-grade air-quality data from the IRCELine monitoring network.
Read the full ENACT news item: https://enact-he.eu/industrial-fire-air-quality-monitoring-brussels/

ETRO-VUB was represented at imec’s ITF World 2026, participating in the “The Future of Media and Entertainment” event.
Rodolphe Valicon De Soete, Colas Schretter, and David Blinder contributed to the sessions on the StageTech Flanders volumetric capturing roadmap and holographic display technology.
They presented a demo showcasing interactive rendering using Gaussian mixture models and holography on a light-field display. Many thanks to Rodolphe and Colas for preparing and presenting the demo at ITF World!

Introduction
This guide explains how to install and configure WireGuard with an MFA overlay using Defguard. The setup consists of three main steps, to be executed after requesting a token from ETRO_ICT@vub.be.
- Activate MFA/TOTP on your account
This secures your Defguard account with two-factor authentication before you configure VPN access. - Install the Defguard client
This installs the application needed to manage and connect to the WireGuard VPN from your device. - Configure and connect to the VPN
This links your device to Defguard using the provided enrollment token and allows you to connect securely to the Brussels VPN location.
Once these steps are completed, your device will be ready to connect to the VPN using WireGuard with MFA authentication.
1) Activate your account with MFA, TOTP
Go to:
Log in with your ETROVUB credentials. Use only your username, without @etrovub.be.
Click Edit profile in the top-right corner.
Enable TOTP — Time-Based One-Time Password — as your two-factor authentication method by clicking on the gear wheel next to TOTP. You may need to do this twice.
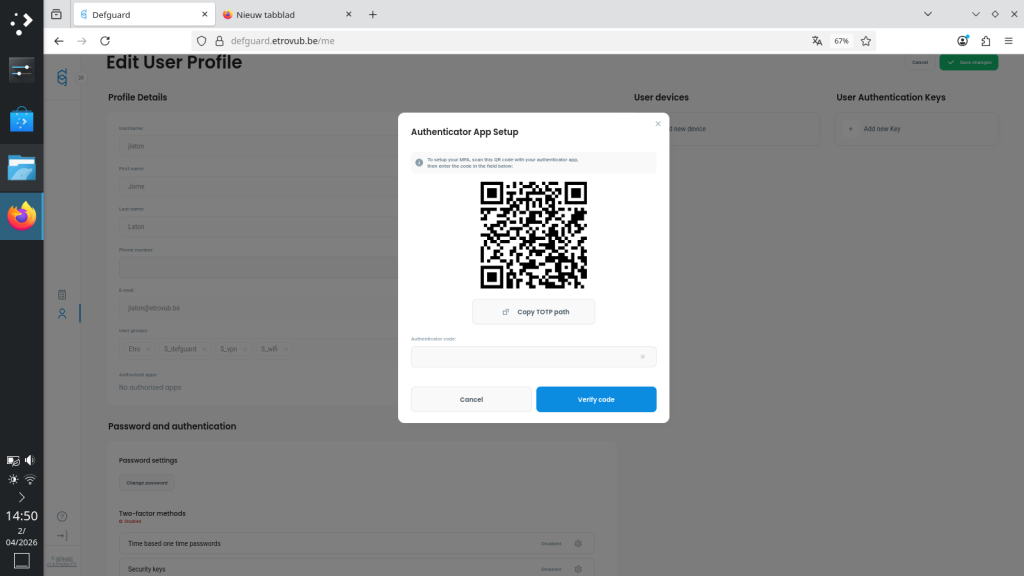
Use an authenticator app, or equivalent, to register Defguard by scanning the QR code. Once registered, enter the one-time password code to confirm.
Recovery codes are not strictly necessary, as ICT can intervene if needed. Click I have saved my codes.
Do not forget to save your changes.
If you are logged out, log back in using your authentication code.
2) Install your Defguard client
Go to::
https://enroll.etrovub.be
Start the enrollment process.
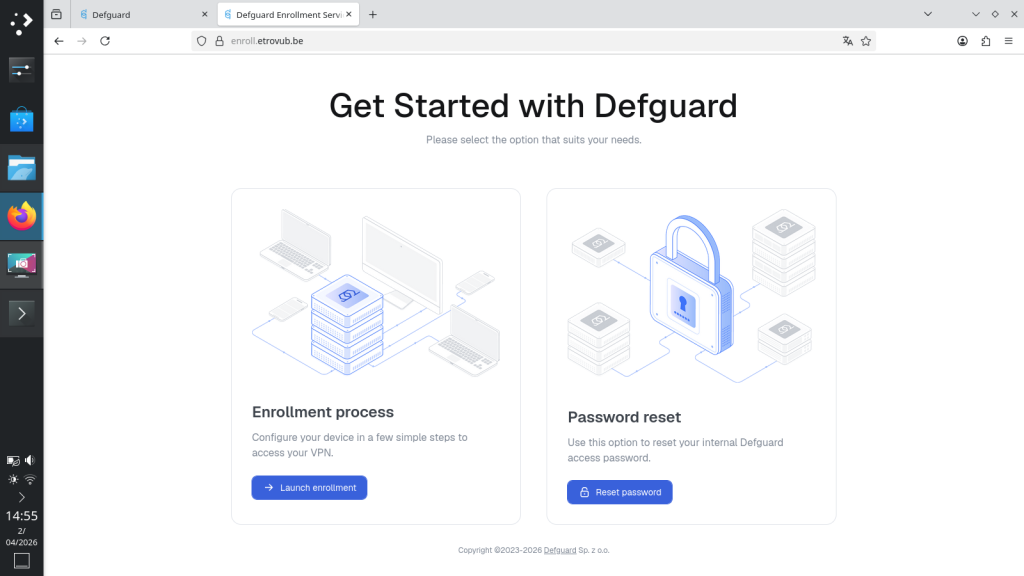
Click Launch enrollment.
You will be asked to enter the token sent by your administrator.
Download and install the client for your operating system.
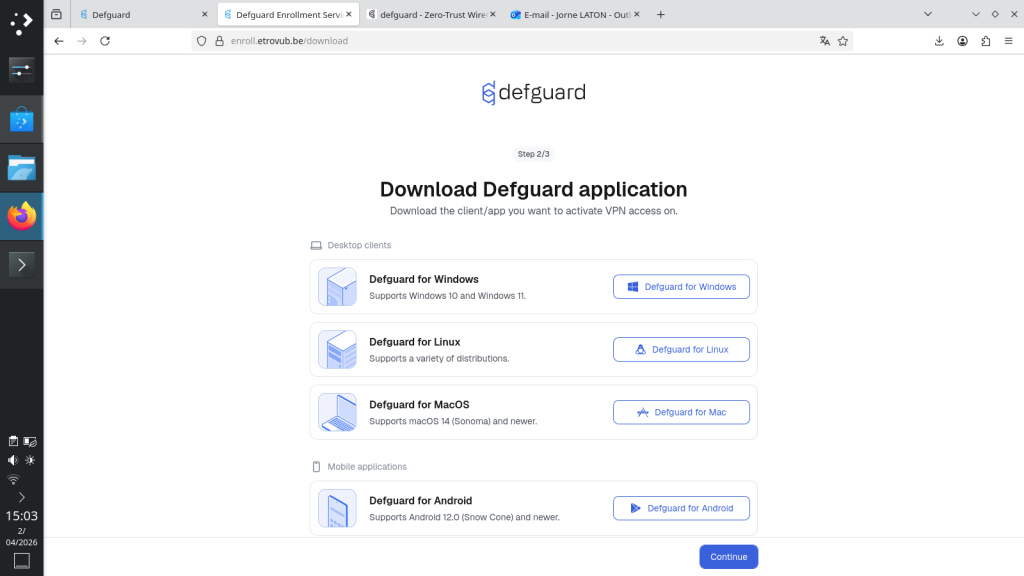
Once the client has been installed, open it
3) Configuration of the connection in the client
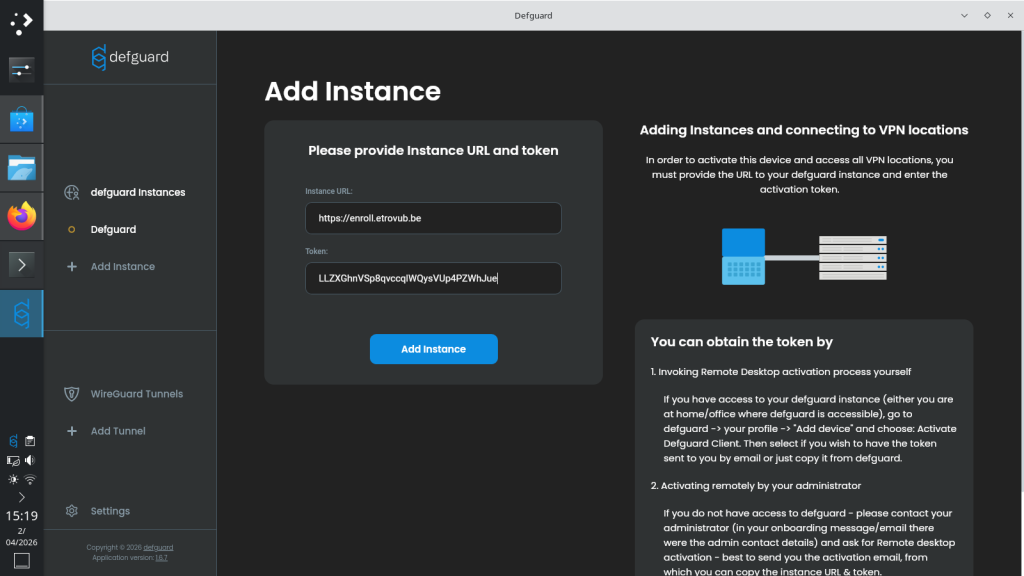
In the Defguard client, click Add instance in the left menu bar.
Enter the URL and token you received from your administrator.
For each supplementary device please request a new token at ETRO_ICT@vub.be
Choose a name for your device.
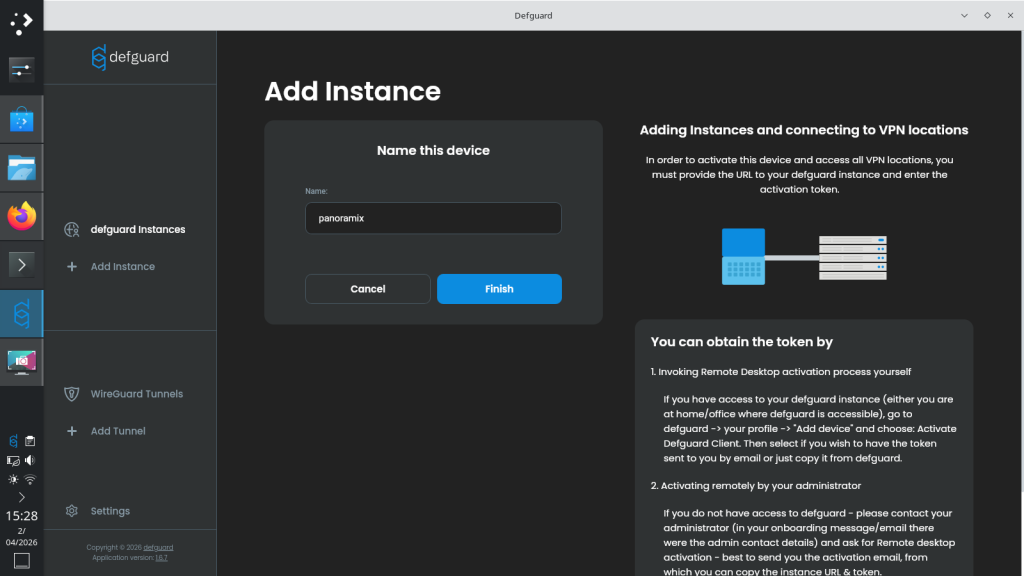
Once the instance has been created, click Connect for the Brussels location.
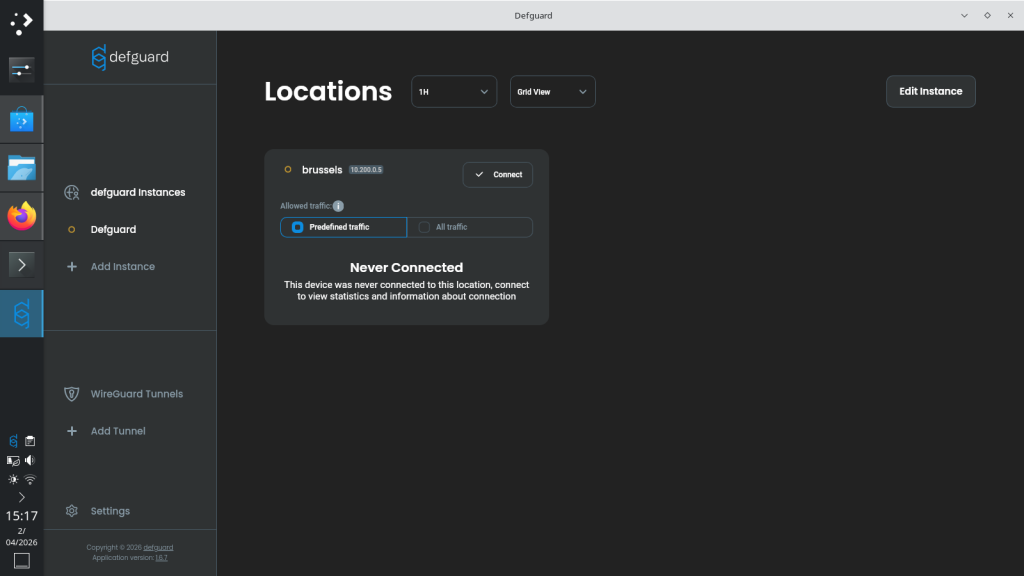
Use MFA to authenticate.
You are now successfully connected.
Good luck! You are virtually there!
4) Your installation not going to plan ?
Perhaps one of the remedies below helps
- Try uninstalling and reinstalling with the Defguard client with admin rights
- Try installing the client directly from e.g. defguard.net or the app store
- Ubuntu needs an extra package;
sudo apt install resolvconf - A token is only valid for 24h, request a new one
- Arch Linux with Nvidia GPU gives white screen? `GDK_BACKEND=x11 WEBKIT_DISABLE_DMABUF_RENDERER=1 defguard-client` does the trick.
ETRO-VUB was pleased to participate in the first Climate Technology Day at Green Energy Park vzw, organised by FACT-VUB and Vrije Universiteit Brussel.
ETRO-VUB was represented by Prof. Johan Stiens, who joined VUB colleagues in welcoming students from different secondary schools for interactive sessions on engineering and climate technology.
The event offered students the opportunity to discover how research and innovation in areas such as electric mobility, sustainable energy systems, and climate technology can help shape a more sustainable future.
We are proud to have contributed to an inspiring day that encouraged the next generation of engineers to engage with one of the most important challenges of our time: tackling climate change.
The world needs climate engineers.
Many thanks to FACT-VUB, Green Energy Park vzw, Vrije Universiteit Brussel, VUB Faculty of Engineering, and all colleagues and partners involved for making this event possible.

On April 21st 2026 at 17:00, Salar Tayebi will defend their PhD entitled “BEYOND CONVENTIONAL METHODS FOR THE CHARACTERIZATION OF INTRA-ABDOMINAL PRESSURE”.
Everybody is invited to attend the presentation in room D.2.01 or online via this link.
This PhD thesis investigates how pressure inside the abdomen, known as intra-abdominal pressure (IAP), can be better understood and monitored, particularly in critically ill patients. Elevated IAP is a clinically important condition: when IAP rises beyond normal levels, it can impair organ function and, in severe cases, lead to life-threatening complications. For this reason, there is growing recognition that IAP should be monitored more systematically, similar to other vital signs in intensive care. The thesis begins by outlining the mechanisms that lead to increased abdominal pressure. IAP can rise either because the abdominal cavity becomes less compliant or because its internal volume increases, often due to fluid accumulation during severe illness. Increases in abdominal pressure can influence other body compartments, including the chest and the brain, highlighting the systemic nature of the problem. From a physical perspective, the abdomen is described as a semi-enclosed compartment bounded by both rigid and flexible structures. The thesis then reviews current techniques for measuring IAP. Clinically, IAP is most commonly assessed indirectly via the urinary bladder, which serves as a reference standard. However, this method is intermittent and not ideally suited for continuous monitoring. As a result, there is increasing interest in alternative approaches that estimate IAP non-invasively, for example by analyzing changes in body shape or tissue mechanics. To explore this, the thesis examines the relationship between IAP and anthropometric parameters in a cohort of intensive care patients. The results show that specific body measurements are associated with IAP. These findings support the idea that externally measurable changes in body geometry may serve as useful indicators of internal pressure. Building on this concept, the thesis investigates microwave reflectometry as a novel non-invasive method for IAP monitoring. This technique uses low-power electromagnetic waves to probe the abdominal wall and detect structural changes. Through a combination of computational models, laboratory experiments, and clinical studies, the work demonstrates that changes in abdominal wall displacement can be reliably captured. In particular, the time of flight of reflected signals emerges as a robust parameter for tracking IAP-related changes. Finally, the thesis addresses an important practical issue: the dependence of IAP measurements on body position and measurement site. Clinical studies show that IAP values can vary significantly with posture and with the location of measurement, emphasizing that IAP is not a fixed quantity but a context-dependent parameter. In summary, this thesis provides an integrated understanding of intra-abdominal pressure from physiological, methodological, and technological perspectives. It highlights the limitations of current measurement techniques and presents non-invasive alternatives that could enable more continuous and patient-friendly monitoring in the future.
The Weight of the Cloud: Navigating Digital Mediation, Human Meaning, and Planetary Responsibility
Friday 10 April 2026
Vrije Universiteit Brussel – Auditorium I.2.02
The Centre for Ethics and Humanism (EtHu) warmly invites faculty members, researchers, and Master and Research Master students to the 2026 EtHu Research Day: The Weight of the Cloud: Navigating Digital Mediation, Human Meaning, and Planetary Responsibility.
This research day brings together philosophical, ethical, ecological, and technological perspectives to reflect on the implications of contemporary cloud-based technologies. While digital life is often imagined as light and immaterial, the infrastructures that sustain it—from data centres to global resource extraction—carry significant existential, social, and ecological weight. The event offers a space for critical discussion on how digital mediation reshapes human meaning and responsibility in a computational world.
The programme features keynote lectures by Prof. Dr. Vincent Blok (Erasmus University Rotterdam) and Prof. Dr. ir. Johan Stiens (Vrije Universiteit Brussel), as well as paper presentations by Aaron A. Bernstein (Georgia College & State University), Deborah Marber (De Montfort University), Massimiliano Simons and Joe Litobarski (Maastricht University), Amanda Platek (University of Copenhagen), Daniel Bjorklund (Western University), and Agostino Cera (Università di Ferrara).
The research day is open to faculty members, researchers, and Master and Research Master students. We warmly encourage you to share this invitation within your network.
Register here
More information is available via the EtHu website.
We hope to welcome many of you on 10 April.
New video on the INTOWALL project .
Johan Stiens gave a lecture @ the atheneum Geel in the framework of PACT
“Technology, Humanity, and the Climate Imperative: Engineering a Sustainable Future”
Climate change is no longer a distant threat—it is a defining reality shaping our planet, economies, and societies. This keynote invites participants to take a bird’s-eye view of the interconnected forces driving this transformation and to explore how technology, data, and global citizenship can converge to create a sustainable future. We begin with critical observations on climate change and its cascading impact on population dynamics and economic resilience. From there, we examine the evolving energy mix, where renewable sources are not just alternatives but imperatives, demanding innovation in materials, transistors, and processors that power both ICT and solar technologies.
As we enter the data era, ICT systems and smart IoT solutions are unlocking unprecedented sectorial benefits—from MedTech and HealthTech to agri-food and construction—while enabling biodiversity and sustainability at scale. These advances are not merely technical; they represent a societal shift toward intelligent, resource-efficient ecosystems. Drawing on decades of experience in sensor technology development and active engagement with global organizations, this talk will challenge academia, industry, and policymakers to embrace technology uptake as a catalyst for systemic change. Ultimately, the question is not only how we innovate, but how we become true global citizens—responsible stewards of the planet we share, and architects of a future where digital intelligence and clean energy work hand in hand to safeguard life on Earth.
FAQ for the Master Applied Computer Science
“Signal Processing in the AI era” was the tagline of this year’s IEEE International Conference on Acoustics, Speech and Signal Processing, taking place in Rhodes, Greece.
In this context, Brent de Weerdt, Xiangyu Yang, Boris Joukovsky, Alex Stergiou and Nikos Deligiannis presented ETRO’s research during poster sessions and oral presentations, with novel ways to process and understand graph, video, and audio data. Nikos Deligiannis chaired a session on Graph Deep Learning, attended the IEEE T-IP Editorial Board Meeting, and had the opportunity to meet with collaborators from the VUB-Duke-Ugent-UCL joint lab.
Featured articles:
- De Weerdt, B. et al., “Designing Transformer Networks for Sparse Recovery of Sequential Data Using Deep Unfolding” (https://ieeexplore.ieee.org/abstract/document/10094712)
- Yang X. et al., “Relevance Propagation through Deep Conditional Random Fields” (https://ieeexplore.ieee.org/abstract/document/10095075)
- Stergiou A. et al., “Play it back: Iterative attention for audio recognition” (https://ieeexplore.ieee.org/abstract/document/10096532, developed at the University of Bristol)
Prof. Lesley De Cruz and her team have been selected for the 2026 EMS (European Meteorological Society) Outreach & Communication Award for their innovative workshop that makes urban climate science accessible and engaging. The project uses LEGO bricks and real-time AI modeling to help participants understand how urban design choices affect local temperature patterns.
The workshop operates through a straightforward cycle: participants build miniature cities with LEGO blocks, a custom Temperature Booth scans the physical model, an AI-powered urban climate model processes the data instantly, and participants immediately observe how design modifications (such as replacing parking lots with parks) alter heat distribution patterns. By focusing on nighttime heat retention, the workshop provides intuitive insights into urban planning and climate resilience without requiring prior scientific background.
Since launch, the project has engaged thousands of participants at public events and science festivals. It has also earned recognition in academic circles, including a second place for Best Student Presentation at the 12th International Conference on Urban Climate (2025) and the Royal Flemish Academy’s Science Communication Prize.
The interdisciplinary team includes researchers from VUB and partner institutions RMI, UGent and KdG. The work demonstrates how combining AI, hands-on engagement, and scientific rigor can bridge the gap between complex climate science and public understanding. The award will be presented at the EMS Annual Meeting in Utrecht on September 7, 2026.
This workshop was made possible thanks to funding from Innoviris.
ETRO will be represented at Brussels Climate Week 2026 by Prof. Johan Stiens, who will take part as one of the VUB speakers during the event. Brussels Climate Week brings together experts working on climate, energy, sustainability and the broader transition agenda. The event will take place in Brussels from 12 to 16 October 2026, offering an opportunity to exchange ideas, connect with partners and contribute to the discussion on innovation and decarbonisation.
On 11 May, the Green Energy Park in Zellik welcomed four fifth-year secondary school classes for a Climate Technology Day organised by VUB. Pupils from Sint-Jozefinstituut Ternat, Koninklijk Atheneum Etterbeek and ZAVO Zaventem took part in a varied STEM programme, discovering how engineering, digital technologies and climate innovation come together in the search for sustainable solutions.
A central contribution came from ETRO VUB, represented by Professor Johan Stiens. In his session on the Internet of Things and the transformative role of Big Data, Stiens made a strong case for engineering as a discipline with enormous societal impact. Through concrete examples from everyday life — from laptops and transport to the buildings around us — he showed how engineers shape the world, often invisibly, and why young people should be encouraged to choose engineering and STEM studies.
The day also introduced pupils to broader VUB expertise in climate technology, including electric mobility, wind energy and the Multi-Energy Living Lab at the Green Energy Park. Demonstrations such as the VUB Formula Student race car and the Smart Digital Table Top helped translate complex energy systems into tangible, inspiring experiences for the students.
By combining scientific insight with hands-on demonstrations, the Climate Technology Day gave pupils a vivid impression of what engineering can mean for the future. For ETRO VUB and Professor Johan Stiens, the event was also an opportunity to highlight the importance of electronics, informatics, IoT and data-driven innovation in addressing society’s major challenges — and to motivate a new generation to become part of that effort.
Ruiqi Chen, Abdessamad Nassihi, and Bruno da Silva proudly represented ETRO at the International Symposium on Circuits and Systems (ISCAS 2026) in Shanghai, one of the leading conferences in the field of circuits and systems. They presented two major contributions pushing the boundaries of power-efficient edge computing.
Featured articles:
- “Power-Efficient Spiking Conversion of Deep Unfolded Transformers”; Ahmed Sadaqa
- “IDSPfree: An FPGA-Based Intrusion Detection System with DSP-Free Design”; Abdessamad Nassihi
Researchers involved in the European ENACT project have shown how wearable environmental sensing technology can help capture real-world air-quality events. Following the industrial fire that broke out in Tubize on 25 May 2026, ENACT environmental wearables deployed in Halle, south of Brussels, recorded clear changes in local air-pollution signals, including increases in nitrogen dioxide and volatile organic compound measurements.
The VUB ETRO department contributes to ENACT’s work on environmental monitoring technologies and data-driven analysis, supporting the development of tools that can help researchers better understand how environmental exposure affects health. The measurements collected during this incident provide a concrete example of how wearable sensing can complement official monitoring networks and contribute to future exposomic risk assessment.
Further analysis will refine the raw sensor readings by comparing them with reference-grade air-quality data from the IRCELine monitoring network.
Read the full ENACT news item: https://enact-he.eu/industrial-fire-air-quality-monitoring-brussels/
ETRO-VUB was represented at imec’s ITF World 2026, participating in the “The Future of Media and Entertainment” event.
Rodolphe Valicon De Soete, Colas Schretter, and David Blinder contributed to the sessions on the StageTech Flanders volumetric capturing roadmap and holographic display technology.
They presented a demo showcasing interactive rendering using Gaussian mixture models and holography on a light-field display. Many thanks to Rodolphe and Colas for preparing and presenting the demo at ITF World!
Introduction
This guide explains how to install and configure WireGuard with an MFA overlay using Defguard. The setup consists of three main steps, to be executed after requesting a token from ETRO_ICT@vub.be.
- Activate MFA/TOTP on your account
This secures your Defguard account with two-factor authentication before you configure VPN access. - Install the Defguard client
This installs the application needed to manage and connect to the WireGuard VPN from your device. - Configure and connect to the VPN
This links your device to Defguard using the provided enrollment token and allows you to connect securely to the Brussels VPN location.
Once these steps are completed, your device will be ready to connect to the VPN using WireGuard with MFA authentication.
1) Activate your account with MFA, TOTP
Go to:
Log in with your ETROVUB credentials. Use only your username, without @etrovub.be.
Click Edit profile in the top-right corner.
Enable TOTP — Time-Based One-Time Password — as your two-factor authentication method by clicking on the gear wheel next to TOTP. You may need to do this twice.
Use an authenticator app, or equivalent, to register Defguard by scanning the QR code. Once registered, enter the one-time password code to confirm.
Recovery codes are not strictly necessary, as ICT can intervene if needed. Click I have saved my codes.
Do not forget to save your changes.
If you are logged out, log back in using your authentication code.
2) Install your Defguard client
Go to::
https://enroll.etrovub.be
Start the enrollment process.
Click Launch enrollment.
You will be asked to enter the token sent by your administrator.
Download and install the client for your operating system.
Once the client has been installed, open it
3) Configuration of the connection in the client
In the Defguard client, click Add instance in the left menu bar.
Enter the URL and token you received from your administrator.
For each supplementary device please request a new token at ETRO_ICT@vub.be
Choose a name for your device.
Once the instance has been created, click Connect for the Brussels location.
Use MFA to authenticate.
You are now successfully connected.
Good luck! You are virtually there!
4) Your installation not going to plan ?
Perhaps one of the remedies below helps
- Try uninstalling and reinstalling with the Defguard client with admin rights
- Try installing the client directly from e.g. defguard.net or the app store
- Ubuntu needs an extra package;
sudo apt install resolvconf - A token is only valid for 24h, request a new one
- Arch Linux with Nvidia GPU gives white screen? `GDK_BACKEND=x11 WEBKIT_DISABLE_DMABUF_RENDERER=1 defguard-client` does the trick.
ETRO-VUB was pleased to participate in the first Climate Technology Day at Green Energy Park vzw, organised by FACT-VUB and Vrije Universiteit Brussel.
ETRO-VUB was represented by Prof. Johan Stiens, who joined VUB colleagues in welcoming students from different secondary schools for interactive sessions on engineering and climate technology.
The event offered students the opportunity to discover how research and innovation in areas such as electric mobility, sustainable energy systems, and climate technology can help shape a more sustainable future.
We are proud to have contributed to an inspiring day that encouraged the next generation of engineers to engage with one of the most important challenges of our time: tackling climate change.
The world needs climate engineers.
Many thanks to FACT-VUB, Green Energy Park vzw, Vrije Universiteit Brussel, VUB Faculty of Engineering, and all colleagues and partners involved for making this event possible.
On April 21st 2026 at 17:00, Salar Tayebi will defend their PhD entitled “BEYOND CONVENTIONAL METHODS FOR THE CHARACTERIZATION OF INTRA-ABDOMINAL PRESSURE”.
Everybody is invited to attend the presentation in room D.2.01 or online via this link.
This PhD thesis investigates how pressure inside the abdomen, known as intra-abdominal pressure (IAP), can be better understood and monitored, particularly in critically ill patients. Elevated IAP is a clinically important condition: when IAP rises beyond normal levels, it can impair organ function and, in severe cases, lead to life-threatening complications. For this reason, there is growing recognition that IAP should be monitored more systematically, similar to other vital signs in intensive care. The thesis begins by outlining the mechanisms that lead to increased abdominal pressure. IAP can rise either because the abdominal cavity becomes less compliant or because its internal volume increases, often due to fluid accumulation during severe illness. Increases in abdominal pressure can influence other body compartments, including the chest and the brain, highlighting the systemic nature of the problem. From a physical perspective, the abdomen is described as a semi-enclosed compartment bounded by both rigid and flexible structures. The thesis then reviews current techniques for measuring IAP. Clinically, IAP is most commonly assessed indirectly via the urinary bladder, which serves as a reference standard. However, this method is intermittent and not ideally suited for continuous monitoring. As a result, there is increasing interest in alternative approaches that estimate IAP non-invasively, for example by analyzing changes in body shape or tissue mechanics. To explore this, the thesis examines the relationship between IAP and anthropometric parameters in a cohort of intensive care patients. The results show that specific body measurements are associated with IAP. These findings support the idea that externally measurable changes in body geometry may serve as useful indicators of internal pressure. Building on this concept, the thesis investigates microwave reflectometry as a novel non-invasive method for IAP monitoring. This technique uses low-power electromagnetic waves to probe the abdominal wall and detect structural changes. Through a combination of computational models, laboratory experiments, and clinical studies, the work demonstrates that changes in abdominal wall displacement can be reliably captured. In particular, the time of flight of reflected signals emerges as a robust parameter for tracking IAP-related changes. Finally, the thesis addresses an important practical issue: the dependence of IAP measurements on body position and measurement site. Clinical studies show that IAP values can vary significantly with posture and with the location of measurement, emphasizing that IAP is not a fixed quantity but a context-dependent parameter. In summary, this thesis provides an integrated understanding of intra-abdominal pressure from physiological, methodological, and technological perspectives. It highlights the limitations of current measurement techniques and presents non-invasive alternatives that could enable more continuous and patient-friendly monitoring in the future.
The Weight of the Cloud: Navigating Digital Mediation, Human Meaning, and Planetary Responsibility
Friday 10 April 2026
Vrije Universiteit Brussel – Auditorium I.2.02
The Centre for Ethics and Humanism (EtHu) warmly invites faculty members, researchers, and Master and Research Master students to the 2026 EtHu Research Day: The Weight of the Cloud: Navigating Digital Mediation, Human Meaning, and Planetary Responsibility.
This research day brings together philosophical, ethical, ecological, and technological perspectives to reflect on the implications of contemporary cloud-based technologies. While digital life is often imagined as light and immaterial, the infrastructures that sustain it—from data centres to global resource extraction—carry significant existential, social, and ecological weight. The event offers a space for critical discussion on how digital mediation reshapes human meaning and responsibility in a computational world.
The programme features keynote lectures by Prof. Dr. Vincent Blok (Erasmus University Rotterdam) and Prof. Dr. ir. Johan Stiens (Vrije Universiteit Brussel), as well as paper presentations by Aaron A. Bernstein (Georgia College & State University), Deborah Marber (De Montfort University), Massimiliano Simons and Joe Litobarski (Maastricht University), Amanda Platek (University of Copenhagen), Daniel Bjorklund (Western University), and Agostino Cera (Università di Ferrara).
The research day is open to faculty members, researchers, and Master and Research Master students. We warmly encourage you to share this invitation within your network.
Register here
More information is available via the EtHu website.
We hope to welcome many of you on 10 April.
New video on the INTOWALL project .
Johan Stiens gave a lecture @ the atheneum Geel in the framework of PACT
“Technology, Humanity, and the Climate Imperative: Engineering a Sustainable Future”
Climate change is no longer a distant threat—it is a defining reality shaping our planet, economies, and societies. This keynote invites participants to take a bird’s-eye view of the interconnected forces driving this transformation and to explore how technology, data, and global citizenship can converge to create a sustainable future. We begin with critical observations on climate change and its cascading impact on population dynamics and economic resilience. From there, we examine the evolving energy mix, where renewable sources are not just alternatives but imperatives, demanding innovation in materials, transistors, and processors that power both ICT and solar technologies.
As we enter the data era, ICT systems and smart IoT solutions are unlocking unprecedented sectorial benefits—from MedTech and HealthTech to agri-food and construction—while enabling biodiversity and sustainability at scale. These advances are not merely technical; they represent a societal shift toward intelligent, resource-efficient ecosystems. Drawing on decades of experience in sensor technology development and active engagement with global organizations, this talk will challenge academia, industry, and policymakers to embrace technology uptake as a catalyst for systemic change. Ultimately, the question is not only how we innovate, but how we become true global citizens—responsible stewards of the planet we share, and architects of a future where digital intelligence and clean energy work hand in hand to safeguard life on Earth.
FAQ for the Master Biomedical Engineering
“Signal Processing in the AI era” was the tagline of this year’s IEEE International Conference on Acoustics, Speech and Signal Processing, taking place in Rhodes, Greece.
In this context, Brent de Weerdt, Xiangyu Yang, Boris Joukovsky, Alex Stergiou and Nikos Deligiannis presented ETRO’s research during poster sessions and oral presentations, with novel ways to process and understand graph, video, and audio data. Nikos Deligiannis chaired a session on Graph Deep Learning, attended the IEEE T-IP Editorial Board Meeting, and had the opportunity to meet with collaborators from the VUB-Duke-Ugent-UCL joint lab.
Featured articles:
- De Weerdt, B. et al., “Designing Transformer Networks for Sparse Recovery of Sequential Data Using Deep Unfolding” (https://ieeexplore.ieee.org/abstract/document/10094712)
- Yang X. et al., “Relevance Propagation through Deep Conditional Random Fields” (https://ieeexplore.ieee.org/abstract/document/10095075)
- Stergiou A. et al., “Play it back: Iterative attention for audio recognition” (https://ieeexplore.ieee.org/abstract/document/10096532, developed at the University of Bristol)
Prof. Lesley De Cruz and her team have been selected for the 2026 EMS (European Meteorological Society) Outreach & Communication Award for their innovative workshop that makes urban climate science accessible and engaging. The project uses LEGO bricks and real-time AI modeling to help participants understand how urban design choices affect local temperature patterns.
The workshop operates through a straightforward cycle: participants build miniature cities with LEGO blocks, a custom Temperature Booth scans the physical model, an AI-powered urban climate model processes the data instantly, and participants immediately observe how design modifications (such as replacing parking lots with parks) alter heat distribution patterns. By focusing on nighttime heat retention, the workshop provides intuitive insights into urban planning and climate resilience without requiring prior scientific background.
Since launch, the project has engaged thousands of participants at public events and science festivals. It has also earned recognition in academic circles, including a second place for Best Student Presentation at the 12th International Conference on Urban Climate (2025) and the Royal Flemish Academy’s Science Communication Prize.
The interdisciplinary team includes researchers from VUB and partner institutions RMI, UGent and KdG. The work demonstrates how combining AI, hands-on engagement, and scientific rigor can bridge the gap between complex climate science and public understanding. The award will be presented at the EMS Annual Meeting in Utrecht on September 7, 2026.
This workshop was made possible thanks to funding from Innoviris.
ETRO will be represented at Brussels Climate Week 2026 by Prof. Johan Stiens, who will take part as one of the VUB speakers during the event. Brussels Climate Week brings together experts working on climate, energy, sustainability and the broader transition agenda. The event will take place in Brussels from 12 to 16 October 2026, offering an opportunity to exchange ideas, connect with partners and contribute to the discussion on innovation and decarbonisation.
On 11 May, the Green Energy Park in Zellik welcomed four fifth-year secondary school classes for a Climate Technology Day organised by VUB. Pupils from Sint-Jozefinstituut Ternat, Koninklijk Atheneum Etterbeek and ZAVO Zaventem took part in a varied STEM programme, discovering how engineering, digital technologies and climate innovation come together in the search for sustainable solutions.
A central contribution came from ETRO VUB, represented by Professor Johan Stiens. In his session on the Internet of Things and the transformative role of Big Data, Stiens made a strong case for engineering as a discipline with enormous societal impact. Through concrete examples from everyday life — from laptops and transport to the buildings around us — he showed how engineers shape the world, often invisibly, and why young people should be encouraged to choose engineering and STEM studies.
The day also introduced pupils to broader VUB expertise in climate technology, including electric mobility, wind energy and the Multi-Energy Living Lab at the Green Energy Park. Demonstrations such as the VUB Formula Student race car and the Smart Digital Table Top helped translate complex energy systems into tangible, inspiring experiences for the students.
By combining scientific insight with hands-on demonstrations, the Climate Technology Day gave pupils a vivid impression of what engineering can mean for the future. For ETRO VUB and Professor Johan Stiens, the event was also an opportunity to highlight the importance of electronics, informatics, IoT and data-driven innovation in addressing society’s major challenges — and to motivate a new generation to become part of that effort.
Ruiqi Chen, Abdessamad Nassihi, and Bruno da Silva proudly represented ETRO at the International Symposium on Circuits and Systems (ISCAS 2026) in Shanghai, one of the leading conferences in the field of circuits and systems. They presented two major contributions pushing the boundaries of power-efficient edge computing.
Featured articles:
- “Power-Efficient Spiking Conversion of Deep Unfolded Transformers”; Ahmed Sadaqa
- “IDSPfree: An FPGA-Based Intrusion Detection System with DSP-Free Design”; Abdessamad Nassihi
Researchers involved in the European ENACT project have shown how wearable environmental sensing technology can help capture real-world air-quality events. Following the industrial fire that broke out in Tubize on 25 May 2026, ENACT environmental wearables deployed in Halle, south of Brussels, recorded clear changes in local air-pollution signals, including increases in nitrogen dioxide and volatile organic compound measurements.
The VUB ETRO department contributes to ENACT’s work on environmental monitoring technologies and data-driven analysis, supporting the development of tools that can help researchers better understand how environmental exposure affects health. The measurements collected during this incident provide a concrete example of how wearable sensing can complement official monitoring networks and contribute to future exposomic risk assessment.
Further analysis will refine the raw sensor readings by comparing them with reference-grade air-quality data from the IRCELine monitoring network.
Read the full ENACT news item: https://enact-he.eu/industrial-fire-air-quality-monitoring-brussels/
ETRO-VUB was represented at imec’s ITF World 2026, participating in the “The Future of Media and Entertainment” event.
Rodolphe Valicon De Soete, Colas Schretter, and David Blinder contributed to the sessions on the StageTech Flanders volumetric capturing roadmap and holographic display technology.
They presented a demo showcasing interactive rendering using Gaussian mixture models and holography on a light-field display. Many thanks to Rodolphe and Colas for preparing and presenting the demo at ITF World!
Introduction
This guide explains how to install and configure WireGuard with an MFA overlay using Defguard. The setup consists of three main steps, to be executed after requesting a token from ETRO_ICT@vub.be.
- Activate MFA/TOTP on your account
This secures your Defguard account with two-factor authentication before you configure VPN access. - Install the Defguard client
This installs the application needed to manage and connect to the WireGuard VPN from your device. - Configure and connect to the VPN
This links your device to Defguard using the provided enrollment token and allows you to connect securely to the Brussels VPN location.
Once these steps are completed, your device will be ready to connect to the VPN using WireGuard with MFA authentication.
1) Activate your account with MFA, TOTP
Go to:
Log in with your ETROVUB credentials. Use only your username, without @etrovub.be.
Click Edit profile in the top-right corner.
Enable TOTP — Time-Based One-Time Password — as your two-factor authentication method by clicking on the gear wheel next to TOTP. You may need to do this twice.
Use an authenticator app, or equivalent, to register Defguard by scanning the QR code. Once registered, enter the one-time password code to confirm.
Recovery codes are not strictly necessary, as ICT can intervene if needed. Click I have saved my codes.
Do not forget to save your changes.
If you are logged out, log back in using your authentication code.
2) Install your Defguard client
Go to::
https://enroll.etrovub.be
Start the enrollment process.
Click Launch enrollment.
You will be asked to enter the token sent by your administrator.
Download and install the client for your operating system.
Once the client has been installed, open it
3) Configuration of the connection in the client
In the Defguard client, click Add instance in the left menu bar.
Enter the URL and token you received from your administrator.
For each supplementary device please request a new token at ETRO_ICT@vub.be
Choose a name for your device.
Once the instance has been created, click Connect for the Brussels location.
Use MFA to authenticate.
You are now successfully connected.
Good luck! You are virtually there!
4) Your installation not going to plan ?
Perhaps one of the remedies below helps
- Try uninstalling and reinstalling with the Defguard client with admin rights
- Try installing the client directly from e.g. defguard.net or the app store
- Ubuntu needs an extra package;
sudo apt install resolvconf - A token is only valid for 24h, request a new one
- Arch Linux with Nvidia GPU gives white screen? `GDK_BACKEND=x11 WEBKIT_DISABLE_DMABUF_RENDERER=1 defguard-client` does the trick.
ETRO-VUB was pleased to participate in the first Climate Technology Day at Green Energy Park vzw, organised by FACT-VUB and Vrije Universiteit Brussel.
ETRO-VUB was represented by Prof. Johan Stiens, who joined VUB colleagues in welcoming students from different secondary schools for interactive sessions on engineering and climate technology.
The event offered students the opportunity to discover how research and innovation in areas such as electric mobility, sustainable energy systems, and climate technology can help shape a more sustainable future.
We are proud to have contributed to an inspiring day that encouraged the next generation of engineers to engage with one of the most important challenges of our time: tackling climate change.
The world needs climate engineers.
Many thanks to FACT-VUB, Green Energy Park vzw, Vrije Universiteit Brussel, VUB Faculty of Engineering, and all colleagues and partners involved for making this event possible.
On April 21st 2026 at 17:00, Salar Tayebi will defend their PhD entitled “BEYOND CONVENTIONAL METHODS FOR THE CHARACTERIZATION OF INTRA-ABDOMINAL PRESSURE”.
Everybody is invited to attend the presentation in room D.2.01 or online via this link.
This PhD thesis investigates how pressure inside the abdomen, known as intra-abdominal pressure (IAP), can be better understood and monitored, particularly in critically ill patients. Elevated IAP is a clinically important condition: when IAP rises beyond normal levels, it can impair organ function and, in severe cases, lead to life-threatening complications. For this reason, there is growing recognition that IAP should be monitored more systematically, similar to other vital signs in intensive care. The thesis begins by outlining the mechanisms that lead to increased abdominal pressure. IAP can rise either because the abdominal cavity becomes less compliant or because its internal volume increases, often due to fluid accumulation during severe illness. Increases in abdominal pressure can influence other body compartments, including the chest and the brain, highlighting the systemic nature of the problem. From a physical perspective, the abdomen is described as a semi-enclosed compartment bounded by both rigid and flexible structures. The thesis then reviews current techniques for measuring IAP. Clinically, IAP is most commonly assessed indirectly via the urinary bladder, which serves as a reference standard. However, this method is intermittent and not ideally suited for continuous monitoring. As a result, there is increasing interest in alternative approaches that estimate IAP non-invasively, for example by analyzing changes in body shape or tissue mechanics. To explore this, the thesis examines the relationship between IAP and anthropometric parameters in a cohort of intensive care patients. The results show that specific body measurements are associated with IAP. These findings support the idea that externally measurable changes in body geometry may serve as useful indicators of internal pressure. Building on this concept, the thesis investigates microwave reflectometry as a novel non-invasive method for IAP monitoring. This technique uses low-power electromagnetic waves to probe the abdominal wall and detect structural changes. Through a combination of computational models, laboratory experiments, and clinical studies, the work demonstrates that changes in abdominal wall displacement can be reliably captured. In particular, the time of flight of reflected signals emerges as a robust parameter for tracking IAP-related changes. Finally, the thesis addresses an important practical issue: the dependence of IAP measurements on body position and measurement site. Clinical studies show that IAP values can vary significantly with posture and with the location of measurement, emphasizing that IAP is not a fixed quantity but a context-dependent parameter. In summary, this thesis provides an integrated understanding of intra-abdominal pressure from physiological, methodological, and technological perspectives. It highlights the limitations of current measurement techniques and presents non-invasive alternatives that could enable more continuous and patient-friendly monitoring in the future.
The Weight of the Cloud: Navigating Digital Mediation, Human Meaning, and Planetary Responsibility
Friday 10 April 2026
Vrije Universiteit Brussel – Auditorium I.2.02
The Centre for Ethics and Humanism (EtHu) warmly invites faculty members, researchers, and Master and Research Master students to the 2026 EtHu Research Day: The Weight of the Cloud: Navigating Digital Mediation, Human Meaning, and Planetary Responsibility.
This research day brings together philosophical, ethical, ecological, and technological perspectives to reflect on the implications of contemporary cloud-based technologies. While digital life is often imagined as light and immaterial, the infrastructures that sustain it—from data centres to global resource extraction—carry significant existential, social, and ecological weight. The event offers a space for critical discussion on how digital mediation reshapes human meaning and responsibility in a computational world.
The programme features keynote lectures by Prof. Dr. Vincent Blok (Erasmus University Rotterdam) and Prof. Dr. ir. Johan Stiens (Vrije Universiteit Brussel), as well as paper presentations by Aaron A. Bernstein (Georgia College & State University), Deborah Marber (De Montfort University), Massimiliano Simons and Joe Litobarski (Maastricht University), Amanda Platek (University of Copenhagen), Daniel Bjorklund (Western University), and Agostino Cera (Università di Ferrara).
The research day is open to faculty members, researchers, and Master and Research Master students. We warmly encourage you to share this invitation within your network.
Register here
More information is available via the EtHu website.
We hope to welcome many of you on 10 April.
New video on the INTOWALL project .
Johan Stiens gave a lecture @ the atheneum Geel in the framework of PACT
“Technology, Humanity, and the Climate Imperative: Engineering a Sustainable Future”
Climate change is no longer a distant threat—it is a defining reality shaping our planet, economies, and societies. This keynote invites participants to take a bird’s-eye view of the interconnected forces driving this transformation and to explore how technology, data, and global citizenship can converge to create a sustainable future. We begin with critical observations on climate change and its cascading impact on population dynamics and economic resilience. From there, we examine the evolving energy mix, where renewable sources are not just alternatives but imperatives, demanding innovation in materials, transistors, and processors that power both ICT and solar technologies.
As we enter the data era, ICT systems and smart IoT solutions are unlocking unprecedented sectorial benefits—from MedTech and HealthTech to agri-food and construction—while enabling biodiversity and sustainability at scale. These advances are not merely technical; they represent a societal shift toward intelligent, resource-efficient ecosystems. Drawing on decades of experience in sensor technology development and active engagement with global organizations, this talk will challenge academia, industry, and policymakers to embrace technology uptake as a catalyst for systemic change. Ultimately, the question is not only how we innovate, but how we become true global citizens—responsible stewards of the planet we share, and architects of a future where digital intelligence and clean energy work hand in hand to safeguard life on Earth.